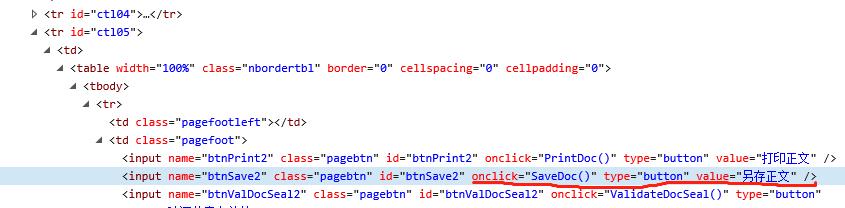
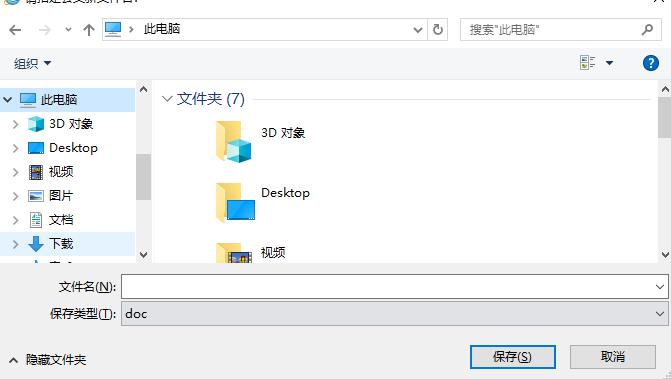
在用python爬取网站文档的过程中遇到了问题,目标文件没有链接,而是一个onclick弹窗,点击后出来一个另存对话框,需要输入文件名,然后点击保存完成下载。这个onclick调用的一个js函数,我贴在下面,请大神帮我看一下,如何用python批量获取这种文件。
functionSaveDoc()
{
varsuffix=g_isUserView?"pdf":"doc";
varfn=IEHelper.IEH_GetNewFileName("请指定新文件名:",suffix);
if(fn!=null&&fn!="")
{
varl=IEHelper.IEH_CopyFile(g_fileName,fn);
if(l==1){
HJAlert("另存文件完成!");
if(g_isUserView){//用户查看时记录文件下载情况
varoperDesc="下载文件序号为【"+form1.hdnSeqnum.value+"】的文件";
hjoa.HJOAHelper.AjaxReportUserOperEvent(2,g_userId,operDesc,form1.hdnSeqnum.value,"","","");
}
}
else{
HJAlert("另存文件出错!");
}
}
}
分 -->
|